 - Praslesham - Malayalam version of Devanagiri Avagraha (U+093D): Details. Already in pipeline with proposed codepoint U+0D3D.
- Praslesham - Malayalam version of Devanagiri Avagraha (U+093D): Details. Already in pipeline with proposed codepoint U+0D3D.-
 - Sign for elongated ഋ (vocalic RR): Already in pipeline with proposed codepoint U+0D44.
- Sign for elongated ഋ (vocalic RR): Already in pipeline with proposed codepoint U+0D44.  - Sign for ഌ (vocalic L): Already in pipeline with proposed codepoint U+0D62.
- Sign for ഌ (vocalic L): Already in pipeline with proposed codepoint U+0D62. - Sign for ൡ (vocalic LL)
- Sign for ൡ (vocalic LL)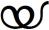 - chillu of യ (YA)
- chillu of യ (YA) - symbol with same meaning as 'th' in date '17-th'. Already in pipeline with proposed codepoint U+0D79
- symbol with same meaning as 'th' in date '17-th'. Already in pipeline with proposed codepoint U+0D79- Malayalam Archaic Cardinal numbers and fractions: Already in pipeline with proposed codepoint U+0D70..75
- Encode chillu
- Possible codepoint for റ്റ (/ta/), if there is no better way to solve the issues described here and here.
- Possible codepoint for signs for semi-vowels (YA, RA, LA, VA), if there is no better way to solve the issues described here.
- Malayalam Eylash-repha. Read details here.
- Redefining U+0D57 (AU length marker)
- Word splitting criterion
- Shaping behavior of ZWJ and ZWNJ and omissions
- Malayalam Collation numbering
- A non-format character way to represent subscript-വ
2005-07-22
Unicode: Suggestions & Proposals




Unicode: Chillu + Consonant => Conjunct ?
Here we discuss the pitfalls in allowing Malayalam Chillu letters to form conjunct with a subsequent consonant. Also suggests the specific scenarios where it should be allowed.
Conventions used
- Pronunciations are transliterated to Latin and written inside forward slashes (//).
- Unicode code points for characters used in this document:
DDA – U+0D22
NNA – U+0D23
RRA – U+0D31
Virama – U+0D4D
We are looking at the issues of writing a text in an old orthography font and reading it in new orthography and vice versa. Specifically, we are looking at the possibility of any Chillu-C1 + C2 sequence forming conjuncts in this mixed context.
There is no General rule for conjunct formation
Argument is through examples:

Uniqueness Rule Violation
I agree that there could be a Chillu-conjunct formation rule for a proper subset of Chillu-C1 + C2 permutations. Even then, due to Uniqueness Rule, we cannot allow Chillu-C1 + C2 and C1 + VIRAMA + C2 forming same conjunct.
This has a side effect: Many words like /alpam/ can potentially have two spellings - one with chillu-LA (![]() )and other with /lpa/ conjunct (
)and other with /lpa/ conjunct (![]() ). Both of these spellings are used synonymously in contemporary Malayalam text. This is very similar to two spellings of 'colour' ('color' is the corresponding American spelling). A British English font should not try to convert 'color' to 'colour'. It should remain as intended by the author. Same should be the case with two spellings of /alpam/ in Malayalam. It should be displayed as intended by the author(s) of the text.
). Both of these spellings are used synonymously in contemporary Malayalam text. This is very similar to two spellings of 'colour' ('color' is the corresponding American spelling). A British English font should not try to convert 'color' to 'colour'. It should remain as intended by the author. Same should be the case with two spellings of /alpam/ in Malayalam. It should be displayed as intended by the author(s) of the text.
So, only C1 + VIRAMA + C2 forms the conjunct.
Exceptions?
Please see discussions on Malayalam eyelash-repha and on /nta/.
2005-07-20
Unicode: issues with /nta/ & /ta/ encoding
Even though, following arguments are detailed only for /nta/, they are equally applicable to /ta/ as well.
Representation of /nta/ is closely related to what ![]() stands for. Malayalam’s behavior of representing /ta/ and /rra/ with same letter had definitely contributed to the confusion of what
stands for. Malayalam’s behavior of representing /ta/ and /rra/ with same letter had definitely contributed to the confusion of what ![]() is - /nta/ or /nrra/. Here are the details of the two ways in which it being used:
is - /nta/ or /nrra/. Here are the details of the two ways in which it being used:
 is used to represent /nrra/ for writing English words like ‘Henry’ (
is used to represent /nrra/ for writing English words like ‘Henry’ ( ) or ‘Enroll’ (
) or ‘Enroll’ ( ) in Malayalam, while
) in Malayalam, while 
 and
and 
- is used in many new orthography fonts to represent /nta/. Typically a font places itself to be somewhere in the middle of new and old orthographies choosing only a convenient subset of conjuncts from old orthography. As an example, Mathrubhumi is the ASCII Malayalam font, which is the closest available to old orthography. Even in that, /nta/ is rendered as . So this usage is very common.
These facts give way to two quite reasonable inputting scenarios:
- There can be Malayalam keyboard layouts with specific keys for Chillu-NA(
 ) and RRA (
) and RRA ( ); and nothing for /nta/.
); and nothing for /nta/.
- Even if, there is a specific method for inputting /nta/, a writer may choose to input /nta/ as Chillu-NA() and then RRA() adjacent to it.
Along with above inputting scenarios following not-so-obvious facts should also be considered:
- Since Malayalam has, just one letter to represent /ta/ and /rra/,
 are essentially the same in the graphemic deep structure: Chillu-NA + RRA
are essentially the same in the graphemic deep structure: Chillu-NA + RRA
- When used as /nta/, is considered a single unit. While in /nrra/ context, it is used as having two separate components. It is evident from the reordering of left vowel signs in following examples:
 ,
,  . The reordering position of the left vowel sign cannot be deduced without knowing the word context from higher text processing. This is the serious unsolved problem if we want to be considered a fallback for stacked .
. The reordering position of the left vowel sign cannot be deduced without knowing the word context from higher text processing. This is the serious unsolved problem if we want to be considered a fallback for stacked .
![]()
- Graphically , can be considered as Chillu-NA + subscript form of RRA. Since Chillus are not encoded (yet), as per
- Consider as a conjunct ligature of NA and RRA. This will lead to much simpler encoding NA + VIRAMA + RRA for . This choice invalidates use of
 for /nta/. Now about fallback.. From
for /nta/. Now about fallback.. From
- Chillu-NA + RRA forms the conjunct ( in every font. Then, as per Uniqueness rule, NA + VIRAMA + RRA should not form /nta/ conjunct. To avoid the reordering problem,
2005-07-19
Unicode: half-റ്റ: to encode or not
There are my reservations on introducing half-റ്റ:
- It can violate Uniqueness Rule because half-റ്റ and റ will have same rendering.
- We are standardizing graphemes (ലിപി) in Unicode; not phonemes (വർണ്ണം). Please refer this article to understand clear distinction between the two in the context of Malayalam.
- Is this a better solution to any existing issues?
Unicode: Word split criterion
A word splitting criterion is required for hyphonation, truncation or wrapping. Following restriction should be enough for Malayalam:
A word ...AB... can be split as:
...A
B...
ONLY IF A is not virama AND B is not a vowel symbol, chillu letter, anuswara or virama.
This rule has got problems with words like ദൃക്സാക്ഷി, which will not get split as ദൃക്+സാക്ഷി (the best split that can happen to this word). But this problem has more to it than just the case of word splitting. See this description.
A word ...AB... can be split as:
...A
B...
ONLY IF A is not virama AND B is not a vowel symbol, chillu letter, anuswara or virama.
This rule has got problems with words like ദൃക്സാക്ഷി, which will not get split as ദൃക്+സാക്ഷി (the best split that can happen to this word). But this problem has more to it than just the case of word splitting. See this description.
2005-07-15
Unicode: Issues with Visible Virama(ചന്ദ്രക്കല)
Please read functions of Visible Virama first.
Unicode system assumes the virama model is equivalent to subjoint model. So Unicode recognizes only function-2 for Visible Virama of Malayalam. This implies that, C1 + Visible Virama + C2 is essentially same as C1 + sign/combining form of C2. Eventhough, it is true in many cases, it does not hold good in some. The specific examples are detailed below.
Issue of /ta/ - റ്റ (RRA+VIRAMA+RRA)
ZWJ and ZWNJ are format characters, directing a font to select from two or more semantically same renderings. Since /ta/ is not encoded, it is possible to produce two semantically different words, which differ only by ZWNJ in their Unicode representation:
കാറ്റാണി meaning 'Car Queen' and shows Visible Virama.
കാറ്റാണി meaning 'this wind is..' and does not show Visible Virama.
This specific issue could be resolved by encoding /ta/.
Issue of symbols for semi-vowel
Malayalam Unicode does not encode the symbols of semi-vowels: യ(YA), ര(RA), ല(LA), വ(VA). As in the previous case, we can produce two semantically different words different only by ZWNJ:
പന്ത്രണ്ട് meaning 'ball-two'. Visible Virama assumes function 1 here.
പന്ത്രണ്ട് (meaning 'twelve')
Another example pairs where Visible Virama assuming function 3:
സത്യജ്ഞൻ, സത്യജ്ഞൻ
സത്രക്ഷണം, സത്രക്ഷണം
This specific issue can be resolved by encoding symbols for above mentioned semi-vowels also.
Issue is not specific to റ്റ or semi-vowels
Consider the word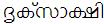 . It is wrong to render it as
. It is wrong to render it as 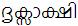 . The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .
. The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .
Implications
Thus, it is 'unsafe' to use function-1 and 3 of Visible Virama. Unfortunately, in many cases, it is difficult/impossible to decide which function of Visible Virama is being used without seeing the whole word.
This is a serious, unsolved problem in Malayalam Unicode design. By encoding /ta/ and symbols of semi-vowels, we may be able to 'contain' it to an extend. Still the issue of(and other words like that) still remains.
Behaviour of Visible Virama in Unicode system is drastically different from the rest of the graphemes, say, the sign of AA. The sign of AA is rendered if and only if the codepoint for sign of AA is present. But the rendering of Visible Virama is conditional and relies on various factors like font capabilities, whether joiners are used etc. It is very difficult (if not impossible) to get these conditions right for all words and names possible in Malayalam. Instead, we may need to go for simple, straight forward way to encode Visible Virama, exactly like sign of AA.
However, straight forward introduction of Visible Virama as a separate codepoint can violate Uniqueness Rule: Let us assume that Visible Virama(VV) has a code-point separate from Virama. Then, both PA + VV and PA + VIRAMA will get rendered the same - പ്.
There fore, when we introduce Visible Virama into the codespace, Virama should be removed. Then it is essential to adopt the subjoined model with signs/combining forms of all consonants into the codespace. This is essentially rejecting virama model and going for subjoined model with Visible Virama.
This decision would imply following:
Unicode system assumes the virama model is equivalent to subjoint model. So Unicode recognizes only function-2 for Visible Virama of Malayalam. This implies that, C1 + Visible Virama + C2 is essentially same as C1 + sign/combining form of C2. Eventhough, it is true in many cases, it does not hold good in some. The specific examples are detailed below.
Issue of /ta/ - റ്റ (RRA+VIRAMA+RRA)
ZWJ and ZWNJ are format characters, directing a font to select from two or more semantically same renderings. Since /ta/ is not encoded, it is possible to produce two semantically different words, which differ only by ZWNJ in their Unicode representation:
കാറ്റാണി meaning 'Car Queen' and shows Visible Virama.
കാറ്റാണി meaning 'this wind is..' and does not show Visible Virama.
This specific issue could be resolved by encoding /ta/.
Issue of symbols for semi-vowel
Malayalam Unicode does not encode the symbols of semi-vowels: യ(YA), ര(RA), ല(LA), വ(VA). As in the previous case, we can produce two semantically different words different only by ZWNJ:
പന്ത്രണ്ട് meaning 'ball-two'. Visible Virama assumes function 1 here.
പന്ത്രണ്ട് (meaning 'twelve')
Another example pairs where Visible Virama assuming function 3:
സത്യജ്ഞൻ, സത്യജ്ഞൻ
സത്രക്ഷണം, സത്രക്ഷണം
This specific issue can be resolved by encoding symbols for above mentioned semi-vowels also.
Issue is not specific to റ്റ or semi-vowels
Consider the word
 . It is wrong to render it as
. It is wrong to render it as 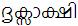 . The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .
. The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .Implications
Thus, it is 'unsafe' to use function-1 and 3 of Visible Virama. Unfortunately, in many cases, it is difficult/impossible to decide which function of Visible Virama is being used without seeing the whole word.
This is a serious, unsolved problem in Malayalam Unicode design. By encoding /ta/ and symbols of semi-vowels, we may be able to 'contain' it to an extend. Still the issue of
(and other words like that) still remains.Behaviour of Visible Virama in Unicode system is drastically different from the rest of the graphemes, say, the sign of AA. The sign of AA is rendered if and only if the codepoint for sign of AA is present. But the rendering of Visible Virama is conditional and relies on various factors like font capabilities, whether joiners are used etc. It is very difficult (if not impossible) to get these conditions right for all words and names possible in Malayalam. Instead, we may need to go for simple, straight forward way to encode Visible Virama, exactly like sign of AA.
However, straight forward introduction of Visible Virama as a separate codepoint can violate Uniqueness Rule: Let us assume that Visible Virama(VV) has a code-point separate from Virama. Then, both PA + VV and PA + VIRAMA will get rendered the same - പ്.
There fore, when we introduce Visible Virama into the codespace, Virama should be removed. Then it is essential to adopt the subjoined model with signs/combining forms of all consonants into the codespace. This is essentially rejecting virama model and going for subjoined model with Visible Virama.
This decision would imply following:
- All fonts will be capable of producing most of the conjucts. Input machanism will decide whether a writer is using conjucts or VV seperated consonants.
- A word written with conjuncts can have different spelling from equivalent one written using VV seperated consonants.
- As of today, reader decides how to see a word by his selection of a font with lot of conjuncts or minimal number of conjuncts. When we go with subjoined model, writer will decide this by his selection of input method.
2005-07-13
Unicode: Concerns unique to /ta/ - റ്റ
This Dravidian alphabet is exclusive to Malayalam among Indic scripts. It stands for both double and single of the sound /ta/ as in റ്റുമാറ്റൊ (single) and പറ്റി (double). For native Malayalam words, this sound never exists outside a conjunct or a double. For words adopted from English, the same റ്റ could represent single /ta/ sound as well. Right now റ്റ is being generated in Unicode as RRA + VIRAMA + RRA. That is, റ്റ is considered the double of റ which sounds /rra/ and obviously different from /ta/.
It is not wrong to write the word ‘സിറ്റി’ as ‘സിററി’. These two words have, different Unicode representations. Instead, Unicode equates ‘സിറ്റി’ to ‘സിറ്റി’ which unfortunately is wrong. That essentially means, Unicode's position of /ta/ as the double of /rra/ is not achieved.
If given a codepoint, റ്റ can form conjuncts with consonants like ന, സ etc to get ന്റ, സ്റ്റ etc. with റ്റ being in the C2 position.
It is not wrong to write the word ‘സിറ്റി’ as ‘സിററി’. These two words have, different Unicode representations. Instead, Unicode equates ‘സിറ്റി’ to ‘സിറ്റി’ which unfortunately is wrong. That essentially means, Unicode's position of /ta/ as the double of /rra/ is not achieved.
If given a codepoint, റ്റ can form conjuncts with consonants like ന, സ etc to get ന്റ, സ്റ്റ etc. with റ്റ being in the C2 position.
2005-07-10
Unicode: Functions of Visible Virama (ചന്ദ്രക്കല)
In Malayalam, following are the functions of Visible Virama:
- Quarter maatra(മാത്ര) vowel sounding similar to ഉ(U), അ(a) or ഇ(I); called /samvruthokaaram/. Examples: അവന് (meaning 'for him'), which is a different lexeme compared to അവൻ(meaning 'he'). That is, graphic function of representing quarter ഇ(I) vowel and phonetic representation of replacing default vowel with the quarter ഇ(I) vowel to the previous letter.
- Indicates the preceding consonant C1 is forming a conjunct with succeeding consonant C2. Example: ഉണ്ട which is same as ഉണ്ട. Here Visible Virama does not produce any sound what so ever - zero മാത്ര(maatra). That is, phonetic function of vowel remover and graphical function of joiner.
- To represent the component boundary in a composite word. Example: ദേശ്രാഗം (meaning 'raga - desh') which is different from ദേശ്രാഗം (meaningless). Another example would be ‘ദൃക്സാക്ഷി’ which should not be rendered as ‘ദൃക്സാക്ഷി’. That is graphical function of boundary seperator(non-joiner) and the phonetic function of removing default vowel from previous letter.
Unicode recognizes functionality-2 alone with visible virama.
Reference: കേരളപാണിനീയം, പീഠിക - A. R. Raja Raja Varma
2005-07-09
Unicode: Malayalam eyelash repha
Following rule could be used to produce eyelash repha conjunct in old orthography font, while producing explicit Chillu-RA in new orthography font:
Chillu-RA + C2 => eyelash-repha over C2, if available in the font.
Example:
![]() +
+ ![]() =>
=> ![]()
We can use joiners – ZWJ & ZWNJ - in their usual meaning: respectively forcing or avoiding the conjunct formation.
As per Uniqueness Rule, RA + VIRAMA + C2 should not form eyelash repha conjunct.
 (with eyelash-repha) and
(with eyelash-repha) and 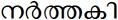 (with explicit Chillu-RA). Both the words are valid, but different renderings of the same word.
(with explicit Chillu-RA). Both the words are valid, but different renderings of the same word.
Unfortunately, all the words with eyelash-repha are not like that. For example, the word  (meaning 'subject matter') has no representation with explicit Chillu-RA. This can violate Uniqueness Rule because it is wrong to write
(meaning 'subject matter') has no representation with explicit Chillu-RA. This can violate Uniqueness Rule because it is wrong to write 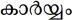 without eyelash-repha. Instead, it should be correctly written as
without eyelash-repha. Instead, it should be correctly written as 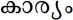 which is a different spelling.
which is a different spelling.
To solve this issue, we may be forced to bring in a separate codepoint for Malayalam eyelash-repha. However, that would remove the reader's choice on viewing or not viewing eyelash-repha in words like .
Subscribe to:
Posts (Atom)