Unicode system assumes the virama model is equivalent to subjoint model. So Unicode recognizes only function-2 for Visible Virama of Malayalam. This implies that, C1 + Visible Virama + C2 is essentially same as C1 + sign/combining form of C2. Eventhough, it is true in many cases, it does not hold good in some. The specific examples are detailed below.
Issue of /ta/ - റ്റ (RRA+VIRAMA+RRA)
ZWJ and ZWNJ are format characters, directing a font to select from two or more semantically same renderings. Since /ta/ is not encoded, it is possible to produce two semantically different words, which differ only by ZWNJ in their Unicode representation:
കാറ്റാണി meaning 'Car Queen' and shows Visible Virama.
കാറ്റാണി meaning 'this wind is..' and does not show Visible Virama.
This specific issue could be resolved by encoding /ta/.
Issue of symbols for semi-vowel
Malayalam Unicode does not encode the symbols of semi-vowels: യ(YA), ര(RA), ല(LA), വ(VA). As in the previous case, we can produce two semantically different words different only by ZWNJ:
പന്ത്രണ്ട് meaning 'ball-two'. Visible Virama assumes function 1 here.
പന്ത്രണ്ട് (meaning 'twelve')
Another example pairs where Visible Virama assuming function 3:
സത്യജ്ഞൻ, സത്യജ്ഞൻ
സത്രക്ഷണം, സത്രക്ഷണം
This specific issue can be resolved by encoding symbols for above mentioned semi-vowels also.
Issue is not specific to റ്റ or semi-vowels
Consider the word
 . It is wrong to render it as
. It is wrong to render it as 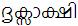 . The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .
. The issue here is this: there is noway a writer using a font with very few conjuncts, can makeout that a reader using a font with almost all conjuncts is viewing this word as .Implications
Thus, it is 'unsafe' to use function-1 and 3 of Visible Virama. Unfortunately, in many cases, it is difficult/impossible to decide which function of Visible Virama is being used without seeing the whole word.
This is a serious, unsolved problem in Malayalam Unicode design. By encoding /ta/ and symbols of semi-vowels, we may be able to 'contain' it to an extend. Still the issue of
(and other words like that) still remains.Behaviour of Visible Virama in Unicode system is drastically different from the rest of the graphemes, say, the sign of AA. The sign of AA is rendered if and only if the codepoint for sign of AA is present. But the rendering of Visible Virama is conditional and relies on various factors like font capabilities, whether joiners are used etc. It is very difficult (if not impossible) to get these conditions right for all words and names possible in Malayalam. Instead, we may need to go for simple, straight forward way to encode Visible Virama, exactly like sign of AA.
However, straight forward introduction of Visible Virama as a separate codepoint can violate Uniqueness Rule: Let us assume that Visible Virama(VV) has a code-point separate from Virama. Then, both PA + VV and PA + VIRAMA will get rendered the same - പ്.
There fore, when we introduce Visible Virama into the codespace, Virama should be removed. Then it is essential to adopt the subjoined model with signs/combining forms of all consonants into the codespace. This is essentially rejecting virama model and going for subjoined model with Visible Virama.
This decision would imply following:
- All fonts will be capable of producing most of the conjucts. Input machanism will decide whether a writer is using conjucts or VV seperated consonants.
- A word written with conjuncts can have different spelling from equivalent one written using VV seperated consonants.
- As of today, reader decides how to see a word by his selection of a font with lot of conjuncts or minimal number of conjuncts. When we go with subjoined model, writer will decide this by his selection of input method.
u got it right now. i was having this thought, that, a text written in old orthography should not be able to convert to new orthography. reason is, new orthography is not designed keeping this purpose in mind. a lot of situations are there where we cannot find a one to one replacement of clusters.
ReplyDelete